데이터베이스에서 인덱싱은 조회 속도를 높이기 위해 많이 사용되는 기법입니다. 우리가 책에서 어떤 내용을 찾을 때 뒤에 인덱스(또는 찾아보기)가 있는 경우에는 빨리 관련된 내용을 찾을 수 있는 것과 같은 원리입니다. 인덱스가 없는 경우와 있는 경우에 얼마나 데이터 조회 속도에 차이가 생기는지 눈으로 직접 확인해보겠습니다.
인덱스가 없는 경우
10만 개의 행이 있는 indexTBL이라는 테이블이 있다고 가정하겠습니다. first_name, last_name, hire_date 세 개의 컬럼으로 구성되어 있고요. 이 테이블의 스키마는 다음과 같습니다.
CREATE TABLE indexTBL (
first_name varchar(14),
last_name varchar(16),
hire_date date
);
이 상황에서 first_name이 Georgi인 데이터를 조회해보겠습니다.
SELECT * FROM indexTBL WHERE first_name = 'Georgi';
약 0.110sec가 소요되었습니다. 10만 개 행인데 이 정도면 양호한 거 아니냐고 하실 수도 있겠지만, 데이터의 양이 100만 개, 1000만 개, 1억 개가 된다고 생각하면 조회하는데 수십 초 이상 소요될 수 있는 위험이 있습니다. 현재는 인덱스가 없기 때문에 Full Table Scan 방식으로 테이블 전체를 검색했습니다.
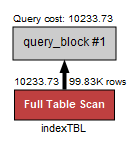
인덱스가 있는 경우
이제 해당 테이블의 first_name 컬럼에 인덱스를 생성해보겠습니다.
CREATE INDEX idx_indexTBL_firstname ON indexTBL(first_name);
그 다음에 다시 first_name이 Georgi인 데이터를 조회해보겠습니다. 이번에는 약 0.015sec가 소요되었습니다.
인덱스 없음 0.110sec VS 0.015sec 인덱스 있음
거의 십분의 1의 시간으로 데이터 조회를 수행했습니다. 인덱스 유무에 따른 조회 시간 차이가 매우 분명하죠?
실행 계획(Execution Plan)을 확인해보면 이번에는 Full Table Scan이 아니라 Non-Unique Key Lookup으로 되어 있습니다. 전체 테이블을 모두 훑은 것이 아니라 인덱스를 사용해서 데이터를 검색했다는 뜻입니다.
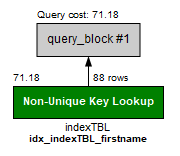
이 상황에서 인덱스를 생성하지 않은 컬럼인 last_name에 조건(WHERE)을 줘서 조회해보면 역시 0.125sec 정도의 긴 시간이 소요됩니다. 이처럼 아무 컬럼에 인덱스를 부여한다고 데이터 조회 속도를 단축시킬 수 있는 것이 아니라, 인덱스를 부여한 컬럼에 조건을 줘서 데이터를 조회할 때 조회 시간 단축 효과를 볼 수 있습니다.
참고자료
[1] 우재남 지음, "이것이 MySQL이다", 한빛미디어(2020)
'DB > SQL' 카테고리의 다른 글
| [MySQL] 스토어드 프로시저 입출력 매개변수 활용 (0) | 2022.10.24 |
|---|---|
| [MySQL] 스토어드 프로시저로 데이터 insert 하기 (0) | 2022.10.23 |
| [MySQL] 인덱스 사용 판단 기준 (0) | 2022.10.22 |
| [MySQL] 테이블 간 관계 맺기(primary key, foreign key) (1) | 2022.10.20 |
| [sqlite3] 이전 행의 데이터를 현재 행에 가져와야 할 때, lead() 함수 (0) | 2022.10.04 |
| [MySQL] 테이블 복원 중에 만난 ERROR 3546 해결 방법 (0) | 2022.09.11 |
| [MySQL] 테이블의 컬럼 개수 확인하기 (0) | 2022.09.10 |
| [MySQL] 윈도우 PC에서 MySQL 환경 변수 설정하는 방법 (0) | 2022.09.09 |