가장 간단한 지도학습 분류(classification) 알고리즘이 kNN(k-Nearest Neighbor)이라면, 가장 간단한 비지도학습 군집(clustering) 알고리즘은 k-means 클러스터링을 꼽을 수 있다. 비지도학습이기 때문에 k-means 클러스터링은 레이블이 없는 데이터들만으로도 작동한다.
k-means 클러스터링은 데이터를 k개의 클러스터(cluster, 무리)로 분류해주는데, 다음과 같은 알고리즘으로 작동한다.
1) 사용자로부터 입력받은 k의 값에 따라, 임의로 클러스터 중심(centroid) k개를 설정해준다.
2) k개의 클러스터 중심으로부터 모든 데이터가 얼마나 떨어져 있는지 계산한 후에, 가장 가까운 클러스터 중심을 각 데이터의 클러스터로 정해준다.
3) 각 클러스터에 속하는 데이터들의 평균을 계산함으로 클러스터 중심을 옮겨준다.
4) 보정된 클러스터 중심을 기준으로 2, 3단계를 반복한다.
5) 더이상 클러스터 중심이 이동하지 않으면 알고리즘을 종료한다.
이 과정을 단계별로 이해할 수 있도록 시각화 해보았다. 아마 쉽게 이해가 될 것이다.
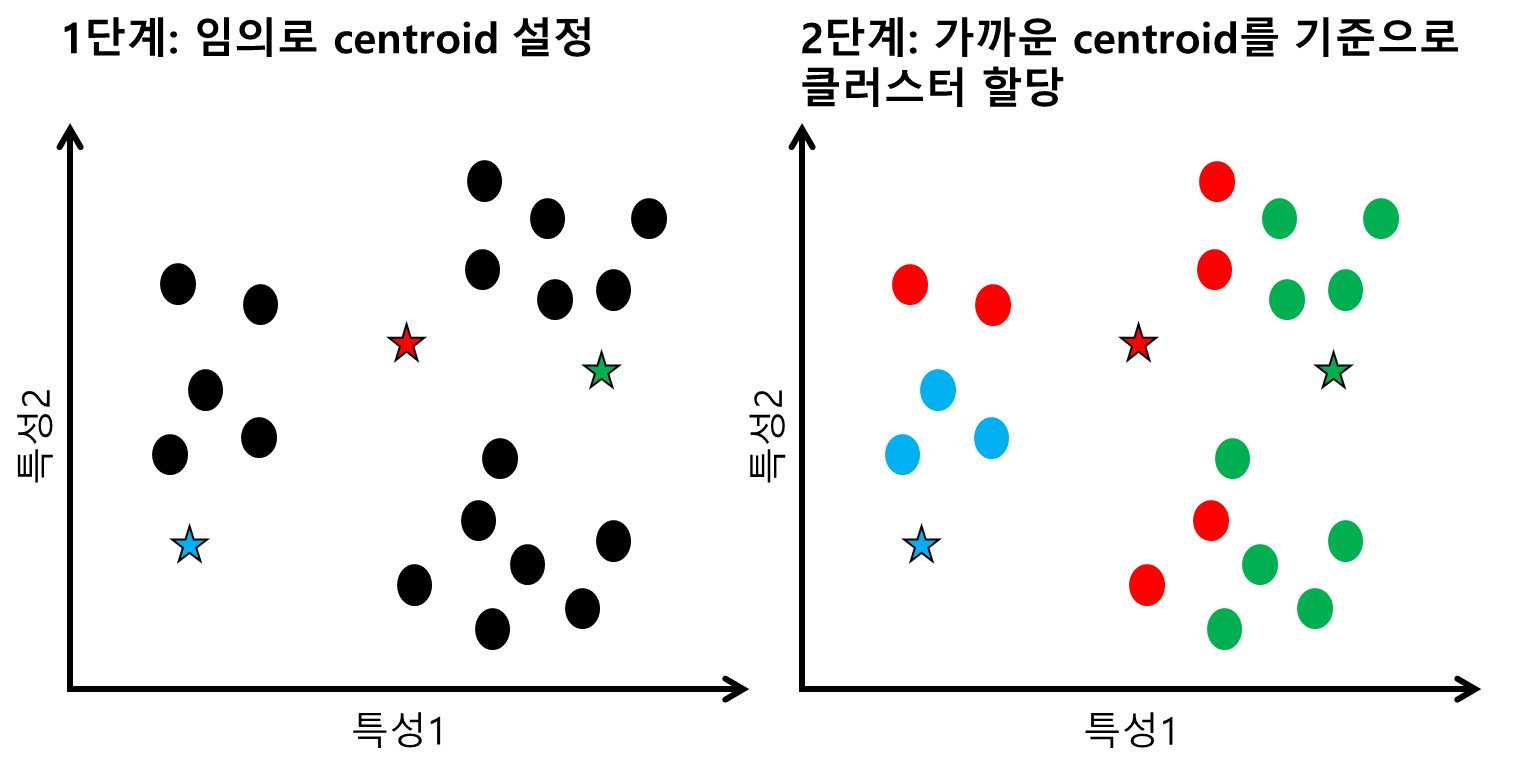
우선 1단계에서는 임의로 centroid가 설정된다. 데이터는 검정 원으로, centroid는 별표로 표시했다. 그 다음에 2단계에서는 각 데이터마다 어떤 centroid가 가까운지 거리를 계산해서 가까운 클러스터에 속하도록 할당해준다. 왼쪽 세개의 데이터가 파랑 클러스터로 할당되었고, 중간부분에 5개 데이터가 빨강 클러스터에 할당되었고, 우측 9개 데이터가 초록 클러스터에 할당되었다.
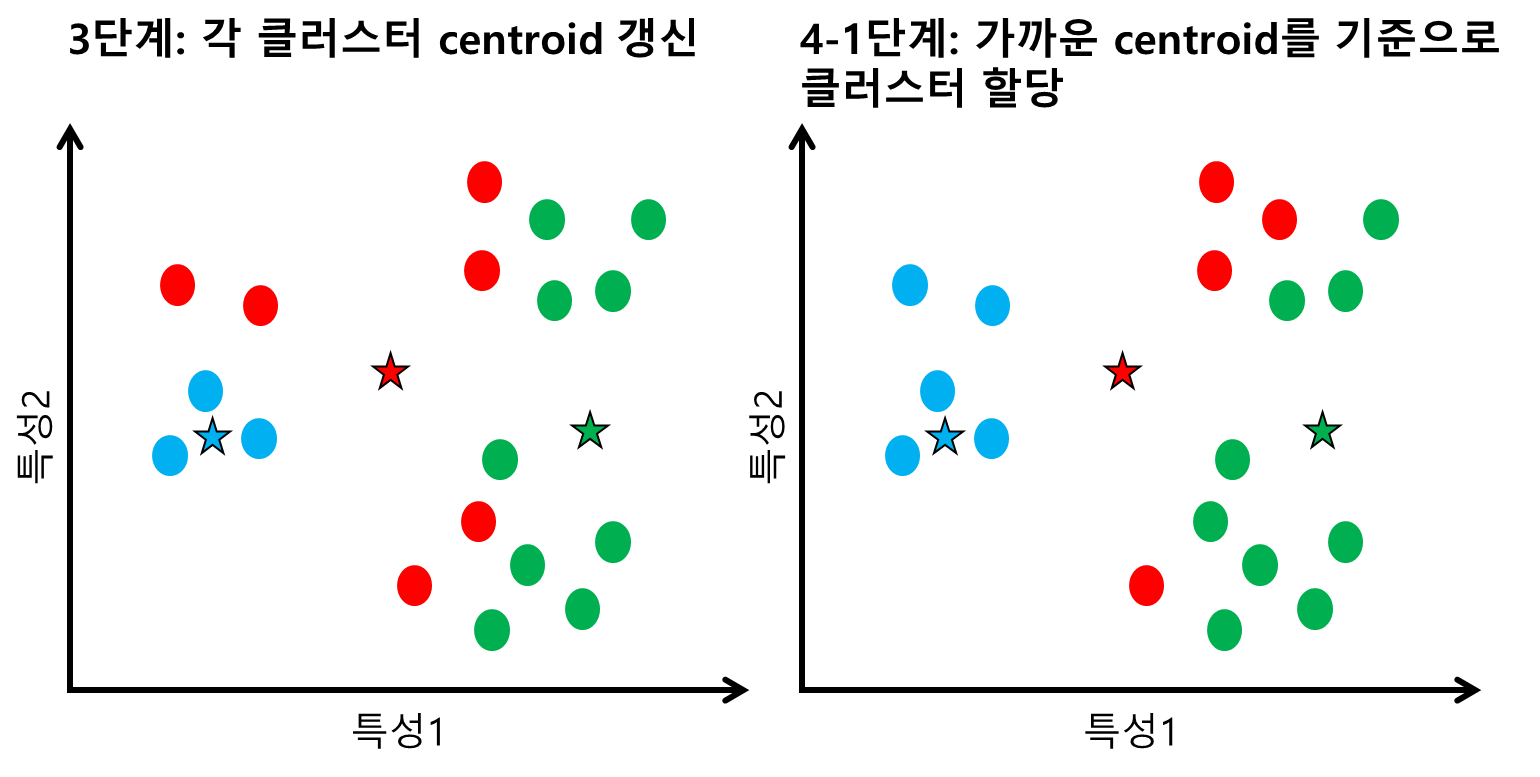
3단계에서는 전 단계에 데이터 포인트들마다 할당된 클러스터에 따라 각 클러스터의 centroid를 갱신해준다. 각 centroid가 클러스터의 중심부분으로 이동한 것을 확인할 수 있을 것이다. 4단계에서는 2, 3단계를 반복한다. 모든 데이터의 클러스터의 변동이 없을 때까지. 4-1단계를 살펴보면, 변경된 centroid에 의해 왼쪽의 5개 데이터가 파랑 클러스터에, 중간부 4개 데이터가 빨강 클러스터에, 좌측 9개가 초록 클러스터에 속하게 되었다.
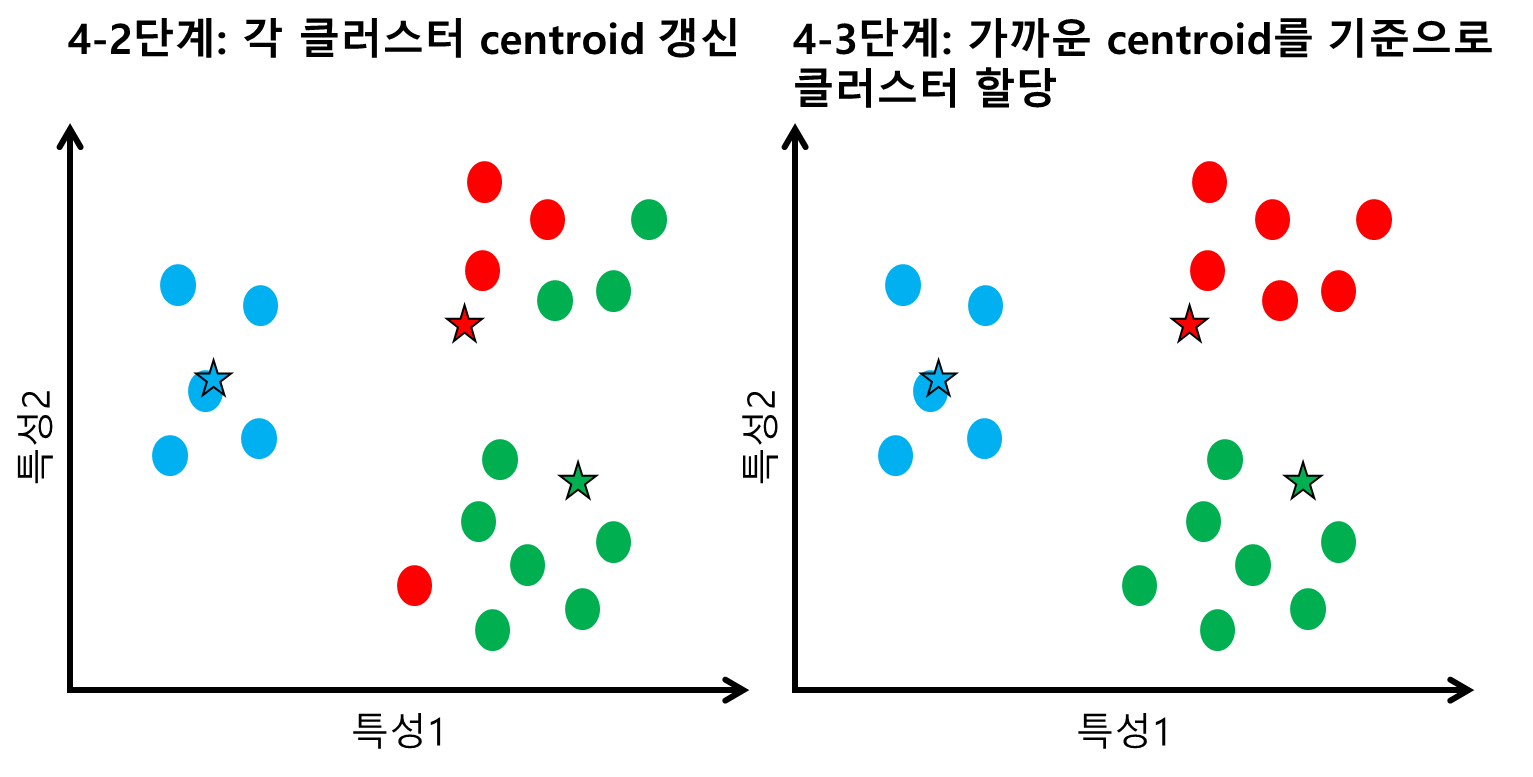
4-2단계에서 클러스터에 따라 다시금 centroid를 갱신했더니 파랑 centroid는 좌측 5개 데이터의 중심부로, 빨강 centroid는 우측 상단 쪽으로, 초록 centroid는 좌측 하단 쪽으로 이동하게 되었다. 그러고 난 후 클러스터를 재할당해준 결과가 4-3단계의 모습이다(이제 거의 제대로 분류가 된 것 같다).

또 다시 클러스터에 따라 centroid를 갱신해줬더니 4-4단계의 그림처럼 되었고, 모든 데이터가 더이상 다른 클러스터로 소속을 바꾸는 일이 없게 되었기에 알고리즘이 종료되었다(5단계).
이 예제는 매우 단순한 예제긴 하지만, k-means 클러스터링이 어떤 방식으로 작동하는지를 이해하는 데에는 부족함이 없다고 생각한다.
잘 읽으셨나요? 유익하셨다면 댓글 또는 공감 부탁드립니다.^^ 10월 9일 한글날입니다. 한글로 포스팅할 수 있게 해주신 세종대왕님께 감사하다는 생각이 문득 드네요. ㅎㅎ
<참고자료>
[1] 김의중 지음, "알고리즘으로 배우는 인공지능, 머신러닝, 딥러닝 입문", 위키북스(2016)
[2] 안드레아스 뮐러, 세라 가이도 지음, 박해선 옮김, "파이썬 라이브러리를 활용한 머신러닝", 한빛미디어(2017)
'Research > ML, DL' 카테고리의 다른 글
| [CNN 알고리즘들] ResNet의 구조 (18) | 2019.11.22 |
|---|---|
| 오차(error)와 잔차(residual)의 차이 (2) | 2019.11.20 |
| 결정 트리(Decision Tree) 알고리즘, ID3 소개 (2) | 2019.10.24 |
| [강화학습] 마코프 프로세스(=마코프 체인) 제대로 이해하기 (11) | 2019.10.15 |
| 유유상종의 진리를 이용한 분류 모델, kNN(k-Nearest Neighbor) (6) | 2019.10.08 |
| [CNN 알고리즘들] GoogLeNet(inception v1)의 구조 (18) | 2019.10.07 |
| [CNN 알고리즘들] VGGNet의 구조 (VGG16) (26) | 2019.06.28 |
| [CNN 알고리즘들] VGG-F, VGG-M, VGG-S의 구조 (2) | 2019.06.27 |